In the field of Natural Language Processing (NLP), language models have become the backbone of innovation—from summarizing massive documents to generating coherent paragraphs with just a few inputs. Among the trailblazers, BART (Bidirectional and Auto-Regressive Transformer) stands out as a transformer model that combines the best of both understanding and generation.
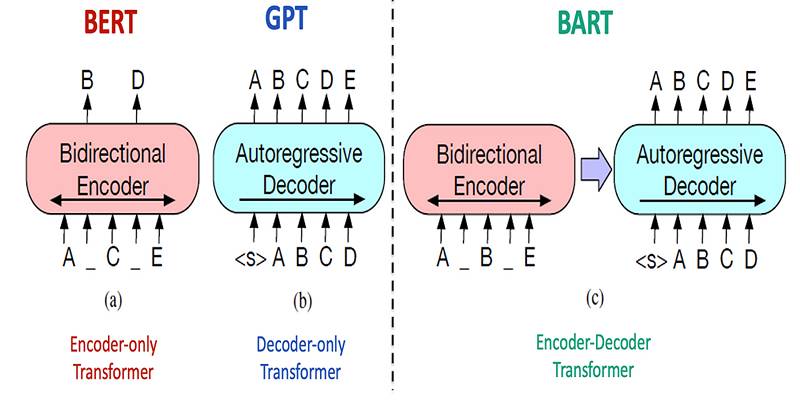
Developed by Facebook AI in 2019, BART was designed to bridge the gap between models like BERT (strong in comprehension) and GPT (excellent in generation). Think of BART as the ultimate hybrid—an NLP powerhouse capable of both deeply understanding context and producing meaningful, fluent text. Let’s explore what makes BART so special, from its core architecture and pre-training strategies to its practical applications and performance against other popular models.
What is BART?
BART is a sequence-to-sequence model built using the transformer architecture. It adopts a bidirectional encoder—like BERT—for understanding text and an autoregressive decoder—like GPT—for generating coherent output one word at a time.
This combination enables BART to effectively handle a wide range of tasks, from text summarization and machine translation to question answering and text generation. But what truly sets BART apart is how it was trained: using corrupted text reconstruction, also known as denoising pre-training.
BART’s Architecture: A Transformer Hybrid
At its core, BART employs the encoder-decoder architecture familiar in many NLP systems. Here’s how it works:
The Encoder – Deep Understanding Through Bidirectionality
The encoder ingests the entire input sequence and processes it bidirectionally—meaning it looks at both the left and right context around every word. It lets it understand nuanced relationships, long-range dependencies, and subtle patterns in the input.
Structurally, it stacks multi-head self-attention layers and feed-forward neural networks, allowing the model to assign dynamic attention to different words based on context. During pre-training, the encoder is often given corrupted inputs—where tokens or spans are deleted, masked, or shuffled—helping it learn robust representations of noisy or incomplete text.
The Decoder – Generating Text with Precision
The decoder works autoregressively, generating one token at a time, each based on the previously generated tokens and the encoder’s output. It also incorporates a cross-attention mechanism to ensure its predictions align closely with the input context. This dual mechanism makes BART incredibly efficient for tasks where both comprehension and generation are needed—such as summarizing articles or translating paragraphs.
Bidirectional Encoder + Autoregressive Decoder = BART’s Power
The fusion of a bidirectional encoder and autoregressive decoder is what gives BART its edge. While BERT is excellent at understanding text and GPT excels in generating it, BART brings both capabilities together in a single architecture. It makes it a strong candidate for complex tasks where both comprehension and generation are needed—such as summarization, where the model must understand an entire document and then condense it into a short, coherent version.
Pre-Training with a Twist: The Power of Text Infilling
What truly makes BART stand out is its unique pre-training objective. Instead of just masking individual words (like BERT) or predicting the next word (like GPT), BART is trained to reconstruct the original text from a corrupted version.
This training approach is called denoising autoencoding, and it uses several techniques to alter the input:
- Token masking: Hiding random words in the text.
- Token deletion: Removing certain words entirely.
- Text infilling: Replacing spans of text with a single mask token.
- Sentence permutation: Shuffling the order of sentences.
- Document rotation: Changing the starting point of the document.
This diversity in corruption makes the model robust across various kinds of noise and enables it to learn both semantic understanding and text reconstruction.
Fine-Tuning BART for Real-World Tasks
After pre-training, BART is fine-tuned on specific tasks to achieve even higher accuracy. Fine-tuning involves training the model on smaller, task-specific datasets so it can adapt its general understanding to a particular application.
Here are a few domains where BART thrives:
- Text Summarization: BART has achieved state-of-the-art results on summarization tasks, condensing lengthy articles into clear, concise summaries.
- Machine Translation: Its encoder-decoder architecture makes BART naturally suited for translating text between languages.
- Question Answering: BART can comprehend a given passage and answer related questions with accurate and contextually appropriate responses.
- Text Generation: Whether it’s creative storytelling or composing emails, BART can generate coherent and relevant text from prompts.
- Sentiment Analysis: With some adjustments, BART can be fine-tuned to classify sentiment or detect opinions in textual data.
BART vs Other Language Models
Understanding how BART compares to other models provides insight into its unique capabilities:
- BART vs. BERT: While BERT excels at understanding context through its bidirectional encoder, it lacks a decoder, limiting its ability to generate text. BART combines BERT's understanding with a decoder, enabling both comprehension and generation.
- BART vs. GPT: GPT models are designed for text generation using a unidirectional approach. BART's bidirectional encoder allows for better context understanding, making it more versatile for tasks that require both understanding and generation.
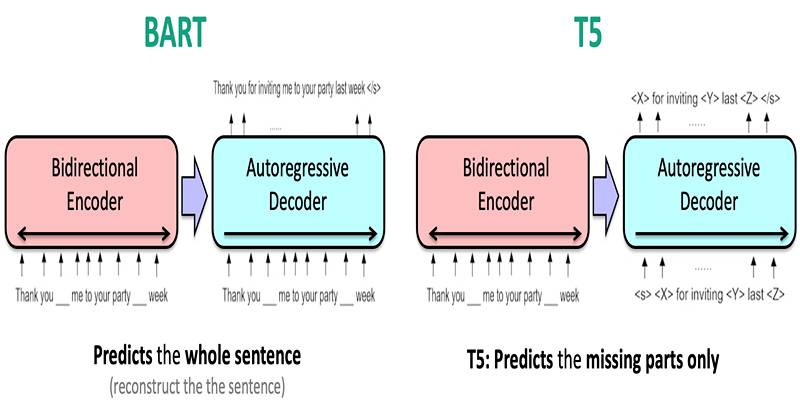
- BART vs. T5: T5 treats every NLP task as a text-to-text problem using a unified framework. BART, while also versatile, uses a different pre-training approach focused on denoising, which can be more effective for certain tasks like summarization.
- BART vs. RoBERTa: RoBERTa is an optimized version of BERT, focusing on understanding tasks. BART extends this by adding a decoder, making it suitable for generative tasks as well.
Why BART Matters in Today’s NLP Landscape
BART’s innovation lies in its versatility. It doesn’t just understand or generate—it does both and does them exceptionally well. Its flexible pre-training, robust architecture and easy integration into modern NLP pipelines make it one of the most impactful models of its time. Whether you're building a chatbot, developing an AI writer, or translating global content, BART can be your go-to model.
Conclusion
BART is not just another transformer model—it’s a fusion of the best ideas from previous NLP architectures, polished into a unified, powerful system. Its encoder-decoder design, denoising pre-training, and seamless integration with tools like Hugging Face make it ideal for a wide array of applications. In a world where text is everywhere, having a model that can understand and generate it with equal ease is a game changer. That’s the brilliance of BART—and why it deserves a top spot in any NLP practitioner’s toolkit.